

On the 14th and the 15th of June 2021, the Centre for Doctoral Training in Next-Generation Computational Modelling arranged a two-day intensive workshop on Natural Language Processing in Python.
Natural Language Processing (NLP) seeks to obtain actionable insights from often vast amounts of language data, and has seen heightened interest in recent years with the increasing popularity of representation learning and machine learning techniques. The aim of the two-day course was to provide an overview of NLP methods used daily by researchers and data scientists alike, and to give insight into current NLP software stacks. The course was provided by Dr. Marco Bonzanini of Bonzanini Consulting; Marco holds a PhD in Information Retrieval, and has worked on a broad range of information management and data science projects, including text analytics, flight safety, and behavioural data.
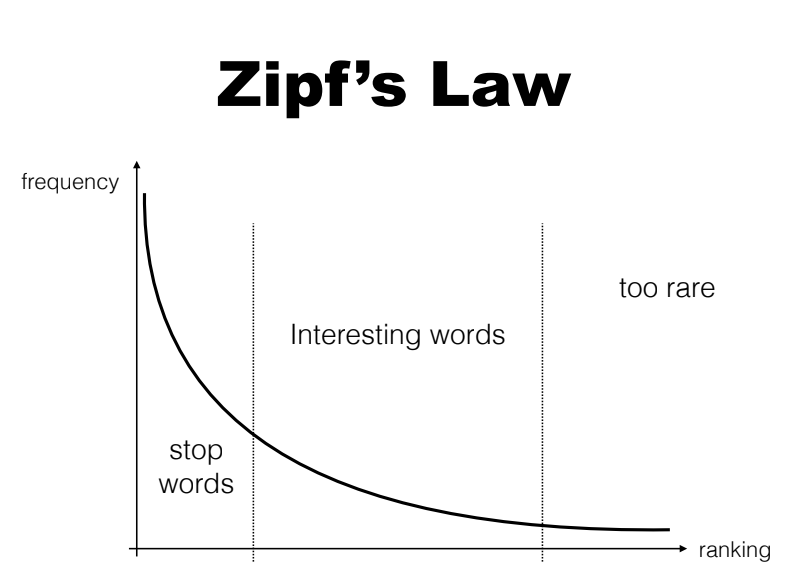
The first day of the course concentrated on the ‘building blocks’ of NLP. In the morning, Dr. Bonzanini introduced the Natural Language Toolkit (NLTK) for Python, and common methods of cleaning and preparing large amounts of textual data. In addition, Zipf’s Law (Figure 1) – that frequencies of numbers are empirically proportional to their rank – was used to introduce the concept of stop words. Stop words are a collection of common words such as determiners and prepositions, which incur substantial computational cost due to their prominence, but do not contribute much towards insight or the context of the language. Various methods for representing words in data structures were also introduced.
SStudents quickly learnt to use these building blocks in more detailed analyses later on in the day. Term frequency-inverse document frequency (TFIDF), a measure of word importance, was used in examining similarities across a collection of texts, or corpus. Dr. Bonzanini introduced the spaCy Python library, and students applied the day’s methods to word associations and document similarities in Lewis Carroll’s Alice in Wonderland, and topic modelling using the GenSim library with applications to newsgroup messages.
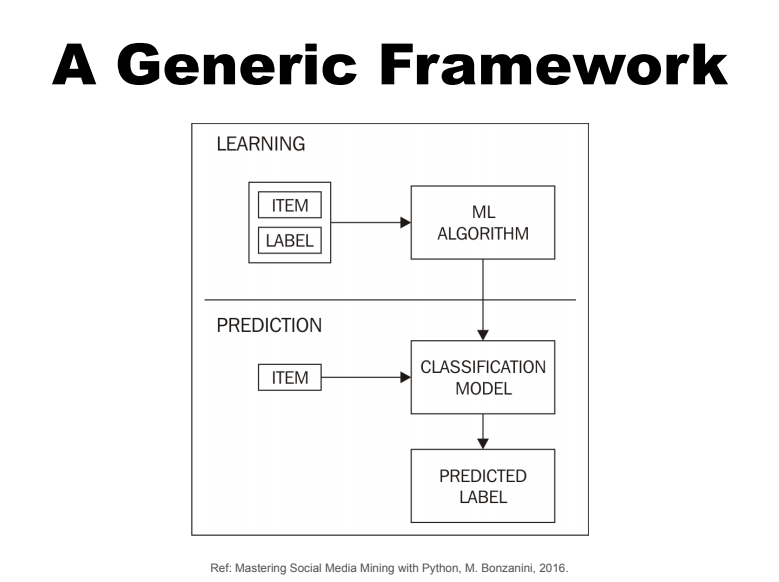
The second day of the course focussed on more advanced applications of NLP. Students were introduced to classifying words and documents, with applications to document organisation (labelling by topic), spam filtering, and word sense disambiguation. Many of the methods introduced revolved around a generic learning-prediction framework (Figure 2), where a modern machine-learning algorithm is used to seed a classification model. These models ranged from binary classification to multi-class classification with one or many labels. Modern techniques, such as k-Fold cross validation, were also combined with established machine learning techniques such as support-vector machines and naive Bayes from the scikit-learn Python library. These techniques were again applied practically in the morning of the second day, classifying news articles from Reuters in the popular Reuters-21578 dataset.
The second day, and the course, ended with discussions and presentations from other participants who were already experienced with NLP, or uses NLP in their studies, to give insight into some of the many potential applications of NLP.
The course provided an excellent, all-round introduction to NLP, with many students revealing that they were now planning on investigating NLP in more detail, both for their PhDs or other studies, and privately.
Written by NGCM students.